Вхід
Общие сведения о вычислительном кластере
Вычислительный кластер - это массив серверов, объединенных некоторой коммуникационной сетью. Каждый вычислительный узел имеет свою оперативную память и работает под управлением своей операционной системы.
Наиболее распространенным является использование однородных кластеров, то есть таких, где все узлы абсолютно одинаковы по своей архитектуре и производительности.
Для каждого кластера имеется выделенный сервер - управляющий узел (frontend). На этом компьютере установлено программное обеспечение, которое активизирует вычислительные узлы при старте системы и управляет запуском программ на кластере. Собственно вычислительные процессы пользователей запускаются на вычислительных узлах, причем они распределяются так, что на каждый процессор приходится не более одного
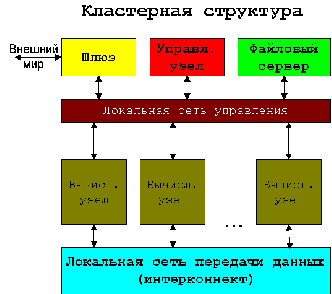
вычислительного процесса. Пользователи имеют домашние каталоги на сервере доступа - шлюзе (этот сервер обеспечивает связь кластера с внешним миром через корпоративную ЛВС или Интернет), непосредственный доступ пользователей на управляющий узел исключается, а доступ на вычислительные узлы кластера возможен (например, для ручного управления компиляцией задачи).
Вычислительный кластер, как правило, работает под управлением одной из разновидностей ОС Unix - многопользовательской многозадачной сетевой операционной системы. В частности, в ИК НАН Украины кластеры работают под управлением ОС Linux - свободно распространяемого варианта Unix. Unix имеет ряд отличий от Windows, которая обычно работает на персональных компьютерах, в частности эти отличие касаются интерфейса с пользователем, работы с процессами и файловой системы.
Существует несколько способов задействовать вычислительные мощности кластера.
- Запускать множество однопроцессорных задач. Это может быть разумным вариантом, если нужно провести множество независимых вычислительных экспериментов с разными входными данными, причем срок проведения каждого отдельного расчета не имеет значения, а все данные размещаются в объеме памяти, доступном одному процессу.
- Запускать готовые параллельные программы. Для некоторых задач доступны бесплатные или коммерческие параллельные программы, которые при необходимости Вы можете использовать на кластере. Как правило, для этого достаточно, чтобы программа была доступна в исходных текстах, реализована с использованием интерфейса MPI на языках С/C++ или Фортран.
- Вызывать в своих программах параллельные библиотеки. Для некоторых областей, напр., линейная алгебра, доступны библиотеки, которые позволяют решать широкий круг стандартных подзадач с использованием возможностей параллельной обработки. Если обращение к таким подзадачам составляет большую часть вычислительных операций программы, то использование такой параллельной библиотеки позволит получить параллельную программу практически без написания собственного параллельного кода. Примером такой библиотеки является SCALAPACK, которая доступна для использования на нашем кластере.
- Создавать собственные параллельные программы. Это наиболее трудоемкий, но и наиболее универсальный способ. Существует несколько вариантов такой работы, в частности, вставлять параллельные конструкции в имеющиеся параллельные программы или создавать с "нуля" параллельную программу.
Параллельные программы на вычислительном кластере работают в модели передачи сообщений - message passing. Это значит, что программа состоит из множества процессов, каждый из которых работает на своем процессоре и имеет свое адресное пространство. Причем непосредственный доступ к памяти другого процесса невозможен, а обмен данными между процессами происходит с помощью операций приема и посылки сообщений. То есть процесс, который должен получить данные, вызывает операцию receive (принять сообщение), и указывает, от какого именно процесса он должен получить данные, а процесс, который должен передать данные другому, вызывает операцию send (послать сообщение) и указывает, какому именно процессу нужно передать эти данные. Эта модель реализована с помощью стандартного интерфейса MPI. Существует несколько реализаций MPI, в том числе бесплатные и коммерческие, переносимые и ориентированные на конкретную коммуникационную сеть. На кластерах СКИТ-1 и СКИТ-2 мы используем коммерческую реализацию Scali (для интерконнекта SCI) и бесплатную OpenMPI (для интерконнекта Infiniband).
Как правило, MPI-программы построены по модели SPMD (одна программа - много данных), то есть для всех процессов имеется только один код программы, а различные процессы хранят различные данные и выполняют свои действия в зависимости от порядкового номера процесса.
Для ускорения работы параллельных программ стоит принять меры для снижения накладных расходов на синхронизацию при обмене данными. Возможно, приемлемым подходом окажется совмещение асинхронных пересылок и вычислений. Для исключения простоя отдельных процессоров нужно наиболее равномерно распределить вычисления между процессами, причем в некоторых случаях может понадобиться динамическая балансировка. Важным показателем, который говорит о том, эффективно ли в программе реализован параллелизм, является загрузка вычислительных узлов, на которых работает программа. Если загрузка на всех или на части узлов далека от 100% - значит, программа неэффективно использует вычислительные ресурсы, т.е. создает большие накладные расходы на обмены данными или неравномерно распределяет вычисления между процессами. Пользователи СКИТ-1 и СКИТ-2 могут посмотреть загрузку через веб-интерфейс для просмотра состояния узлов.
В некоторых случаях для понимания, в чем причина низкой производительности программы и какие именно места в программе необходимо модифицировать, чтобы добиться увеличения производительности, имеет смысл использовать специальные средства анализа производительности - профилировщики и трассировщики.