Вхід
Инструкция Slurm для пользователя. Краткое руководство по запуску
Простая Linux Утилита для Управления Ресурсами (SLURM) - это открытая, надежная и хорошо масштабируемая система управления ресурсами кластера с планировщиком задач, применяемая как для больших, так и для малых Linux-кластеров.
Как менеджер ресурсов кластера, SLURM выполняет три ключевых функции.
Во-первых, он определяет выделенный и/или совместный доступ пользователей к ресурсам (вычислительным узлам) на некоторое время для выполнения ими вычислительных задач.
Во-вторых, он обеспечивает функционирование структуры запуска, выполнения и мониторинга задач (обычно это параллельные задачи) на выделенных узлах.
Наконец, он распределяет ресурсы, управляя очередью ожидающих запуска задач.
Архитектура
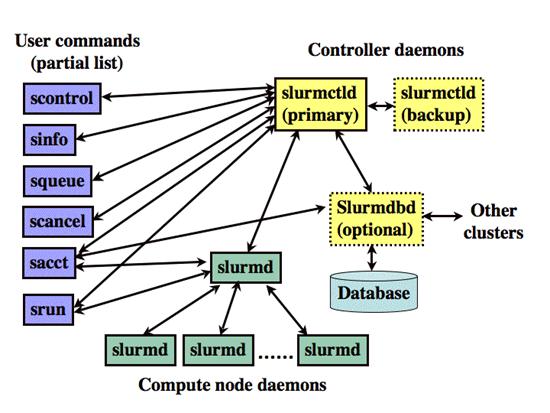
SLURM состоит из сервиса slurmd, запускающегося на каждом вычислительном узле, и центрального сервиса slurmctld, запускающегося на управляющем узле (опционально - с резервной копией управляющего узла).
Сервисы slurmd образуют отказоустойчивую иерархическую структуру. Пользовательские команды включают: sacct, salloc, sattach, sbatch, sbcast, scancel, scontrol, sinfo, smap, squeue, srun, strigger и sview. Все эти команды могут быть запущены как с управляющего сервера, так и с узлов кластера.
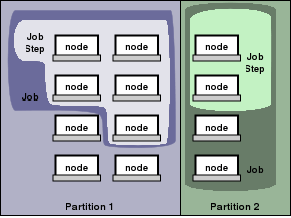
Объекты, управляемые сервисами SLURM, это узлы - вычислительный ресурс SLURM-а, разделы, которые объединяют узлы в логические (возможно, частично перекрывающихся) множества, задачи подмножества ресурсов, выделенных пользователю на указанное количество времени, и шаги задачи, которые являются множествами (возможно параллельных) подзадач в рамках задачи.
Разделы могут рассматриваться как очереди задач, каждая из которых имеет комплекс ограничений, как например ограничение задачи по размеру, по времени выполнения, уровню доступа пользователей и т. д. Задачи в очереди упорядочены по приориету и им выделяются ресурсы в соответствующем разделе.
Как только для задачи выделено множество узлов, пользователь может запускать параллельную работу в виде шагов задачи в любой конфигурации, в пределах выделенных узлов.
Для примера, задача может быть запущена таким образом, что один единственный её шаг выполнения займет все выделенные ресурсы, в то же время несколько подзадач могут независимо друг от друга использовать часть выделенных ресурсов.
Команды
Справочные man-руководства существуют для всех сервисов SLURM, команд, и API функций. Параметр --help выдает краткий перечень возможных параметров команды. Заметьте, что параметры команд не зависят от регистра.
sacct используется, чтобы сообщать задаче или подзадаче учетную информацию о текущих или завершенных задачах.
salloc используется, чтобы выделить ресурсы для задачи в реальном времени. Обычно эта команда используется, чтобы получить ресурсы и shell-доступ к ним. Затем используется командная строка, чтобы выполнять srun-команды для запуска параллельных задач.
sattach используется, чтобы связать потоки стандартного ввода, вывода, ошибок, передачу сигналов с запущенной задачей или подзадачей.
sbatch используется, чтобы запустить скрипт пакетной обработки для дальнейшего выполнения. Скрипт обычно содержит одну или больше srun-команд для запуска параллельных задач.
sbcast используется, чтобы переместить файл из сервера запуска на вычислительный узел задачи. Это может быть использовано, чтобы эффективнее использовать бездисковые вычислительные узлы или обеспечить улучшенную производительность общей файловой системы.
scancel используется, чтобы отменить случайно запущенные или зависшие задачи и подзадачи. Она может также быть использована, чтобы отправить управляющий сигнал всем процессам, связанным с выполняющейся задачей или подзадачей.
scontrol - инструмент администрирования для просмотра и/или изменения состояния SLURM. Отметим, что многие из управляющих команд могут выполняются только суперпользователем.
sinfo сообщает состояние разделов и узлов, управляемых SLURM. Она имеет много способов фильтрации, сортировки, и форматирования выдаваемых результатов.
smap предоставляет графическую информацию о состоянии задач, разделов, и узлов, управляемых SLURM.
squeue докладывает о состоянии задач и подзадач. Она имеет много способов фильтрации, сортировки, и форматирования выдаваемых результатов. По умолчанию, она в первую очередь сообщает о запущенных задачах, зависшие задачи идут следующими по ранжированию.
srun используется, чтобы запустить задачу или подзадачу в реальном времени. srun имеет много различных параметров, чтобы конкретизировать требования к ресурсам, в том числе: минимальное и максимальное количество узлов, количество процессоров, указать какие узлы использовать или не использовать, характеристики узлов (сколько памяти, дискового пространства, определенные требуемые особенности, и т.п.). Задача может содержать множество job шагов, выполняющихся последовательно или в параллельно на независимых или общих узлах в пределах выделенных задаче узлов.
strigger используется для установки, и просмотра триггеров событий. Триггеры событий включают страбатывают в таких случаях, как например выход из строя узлов или задач, приближающихся к их пределу времени.
sview - графический интерфейс пользователя, позволяющий получить и обновить информацию о состоянии задач, разделов, и узлов управляемых SLURM.
Примеры
Для начала мы определяем, какие разделы существуют в системе, какие узлы они включают, и какое состояние системы в целом. Эта информация предоставляется командой sinfo.
$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
scit1 up 44-10:40:0 24 down* n[1001-1024]
scit2 up 2-02:00:00 32 down* n[2001-2032]
scit3* up 20-20:00:0 8 drain* n[3015,3019,3035,3058,3063-3065,3146]
scit3* up 20-20:00:0 14 down* n[3007,3031,3043,3045-3046,3048,3073-3074]
scit3* up 20-20:00:0 1 drain n3006
scit3* up 20-20:00:0 72 alloc n[3008-3010,3012-3014,3016-3017]
scit3* up 20-20:00:0 3 idle n[3049,3135,3143]
scit3gpu up 44-10:40:0 4 idle gpu[1-4]
lite_task up 3:00:00 1 down* n3152
lite_task up 3:00:00 4 idle~ n[3026-3029]
Видим, что есть шесть разделов: scit1, scit2, scit3, scit3gpu, lite_task. Наличие * в названии раздела указывает, что это default раздел для запускаемых задач. Мы видим, что все разделы находятся в состоянии UP.
В каждой строке приводится информация о максимальном времени работы задачи в разделе, количестве узлов, их состоянии и список узлов. Так, в разделе scit3 8 узлов на обслуживании и выключены (drain*) 14 выключены (down;*), 1 в обслуживании (drain).
Потом мы определяем, какие задачи выполняются в системе, используя команду squeue. Поля показывают ID задачи, раздел, название, пользователя, состояние, время работы, количество и список узлов. Посмотрите страницу man для более конкретной информации.
$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
65646 batch chem mike R 24:19 2 adev[7-8]
65647 batch bio joan R 0:09 1 adev14
65648 batch math phil PD 0:00 6 (Resources)
Команда scontrol дает более детальную информацию об узлах, разделах, задачах.
$ scontrol show partition
PartitionName=scit1 TotalNodes=24 TotalCPUs=48 RootOnly=NO
Default=NO Shared=NO Priority=1 State=UP MaxTime=44-10:40:00 Hidden=NO
MinNodes=1 MaxNodes=24 DisableRootJobs=NO AllowGroups=ALL
Nodes=n1[001-024] NodeIndices=0-23
PartitionName=scit2 TotalNodes=32 TotalCPUs=64 RootOnly=NO
Default=NO Shared=NO Priority=1 State=UP MaxTime=2-02:00:00 Hidden=NO
MinNodes=1 MaxNodes=UNLIMITED DisableRootJobs=NO AllowGroups=ALL
Nodes=n2[001-032] NodeIndices=24-55
PartitionName=scit3 TotalNodes=98 TotalCPUs=560 RootOnly=NO
Default=YES Shared=NO Priority=1 State=UP MaxTime=20-20:00:00 Hidden=NO
MinNodes=1 MaxNodes=UNLIMITED DisableRootJobs=NO AllowGroups=ALL
Nodes=n[3106-3125,3127-3143,3146-3150,3006-3010,3012-3017,3019-3025,3030-3038,3043-3069,3073-3074] NodeIndices=61-65,67-72,74-80,85-93,98-124,128-129,141-160,162-178,181-185
PartitionName=scit3gpu TotalNodes=4 TotalCPUs=8 RootOnly=NO
Default=NO Shared=NO Priority=1 State=UP MaxTime=44-10:40:00 Hidden=NO
MinNodes=1 MaxNodes=UNLIMITED DisableRootJobs=NO AllowGroups=ALL
Nodes=gpu[1-4] NodeIndices=188-191
PartitionName=lite_task TotalNodes=5 TotalCPUs=24 RootOnly=NO
Default=NO Shared=NO Priority=1 State=UP MaxTime=03:00:00 Hidden=NO
MinNodes=1 MaxNodes=UNLIMITED DisableRootJobs=NO AllowGroups=ALL
Nodes=n[3026-3029,3152] NodeIndices=81-84,187-187
Получаем детальную информацию об узле:
$ scontrol show node n3025
NodeName=n3025 State=ALLOCATED CPUs=4 AllocCPUs=4 RealMemory=7887 TmpDisk=0
Sockets=4 Cores=1 Threads=1 Weight=1 Features=(null) Reason=(null)
Arch=x86_64 OS=Linux
Информация о задаче:
$ scontrol show job 36622
JobId=36622 UserId=xxxx(yyyy) GroupId=zzzz(zzzz)
Name=d-n35
Priority=4294878198 Partition=scit3 BatchFlag=1
AllocNode:Sid=access:23692 TimeLimit=20-20:00:00 ExitCode=0:0
JobState=RUNNING StartTime=06/01-19:09:01 EndTime=06/22-15:09:01
NodeList=n3025 NodeListIndices=80-80
AllocCPUs=4
ReqProcs=4 ReqNodes=1 ReqS:C:T=1-64.00K:1-64.00K:1-64.00K
Shared=0 Contiguous=0 CPUs/task=0 Licenses=(null)
MinProcs=1 MinSockets=1 MinCores=1 MinThreads=1
MinMemoryNode=0 MinTmpDisk=0 Features=(null)
Dependency=(null) Account=(null) Requeue=1
Reason=None Network=(null)
ReqNodeList=(null) ReqNodeListIndices=
ExcNodeList=(null) ExcNodeListIndices=
SubmitTime=06/01-19:09:01 SuspendTime=None PreSusTime=0
Command=/home/users/xxxxx/test/binary1 d-n35
WorkDir=/home/users/xxxxx/test
Получить ресурсы и запустить задачу можно командой srun. В этом примере выполняется задача /bin/hostname на трех узлах, используется раздел по умолчанию, один процесс на узел. В примере опция -l задает включение указание номера процесса в начале каждой строки.
access$ srun -N3 -l /bin/hostname
0: node03
1: node04
2: node05
Это вариация предыдущего примера, в которой выполняются 4 процесса /bin/hostname, все на одном узле.
access$ srun -n4 -l /bin/hostname
0: node03
1: node03
2: node03
3: node03
Наиболее часто используемый способ работы с кластером - постановка задач в очередь для выполнения.Для этого вместо srun следует использовать команду sbatch, которая ставит задачу в очередь. Стандартный вывод задачи будет направлен в файл slurm-$jobid.out, а поток ошибок в файл slurm-$jobid.err.
Рассмотрим еще один вариант работы - раздельное получение ресурсов и запуск задач в пределах выделеных ресурсов. Команда salloc используется чтобы создать выделенный ресурс и получить оболочку в пределах этого выделенного ресурса.
После этого запускать шаги задачи можно командой srun. После применения последней команды - exit, оболочка, созданная salloc, наконец будет завершена.
SLURM автоматически не перемещает выполняемые файлы программ или файлы данных на выделенные для задачи узлы. Файлы должны существовать либо на локальном диске, либо в некой глобальной файловой системе (например NFS или Lustre).
SLURM предоставляет инструмент sbcast для перемещения файлов в местное хранилище на выделенных узлах. В этом примере используется sbcast, чтобы переместить программу a.out в /tmp/joe.a.out на выделенные узлы. После выполнения программы мы удаляем её из местного хранилища
access$ salloc -N10 bash
$ sbcast a.out /tmp/joe.a.out
Granted job allocation 471
$ srun /tmp/joe.a.out
Result is 3.14159
$ srun rm /tmp/joe.a.out
$ exit
salloc: Relinquishing job allocation 471
В этом примере, мы подаем пакетное задание, получаем его статус и отменяем его.
access$ sbatch test
srun: jobid 473 submitted
access$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
473 batch test jill R 00:00 1 node09
access$ scancel 473
access$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
MPI
Характер использования MPI зависит от того, какой вид MPI используется. Есть три отличные друг от друга последовательности действий, используемых этими различными типами MPI.
- SLURM непосредственно запускает задачи и выполняет инициализацию коммуникаций (MPICH2, MPICH-GM, MPICH-MX, MVAPICH, MVAPICH2 и некоторые методы MPICH1).
- SLURM выделяет ресурсы, для задачи а затем mpirun запускает задачи, используя инфраструктуру SLURM (OPENMPI, LAM/MPI и HP-MPI).
- SLURM выделяет ресурсы, для задачи а затем mpirun запускает задачи, используя при этом любой механизм кроме SLURM, как например SSH или RSH (BlueGene MPI и некоторые методы MPICH1). Эти задачи инициируются за пределами области контролируемой или видимой из SLURM. Поэтому в скрипте эпилога (epilog) SLURM необходимо предусмотреть средства принудительного останова процессов, чтобы можно было избавиться от этой задачи, когда у нее заберут выделенные для неё ресурсы.
Поддержка Мульти-ядерных/Многопоточных Архитектур
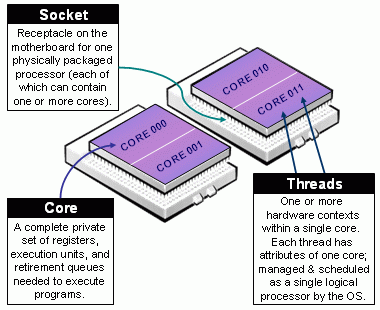
Socket/Core/Thread - иллюстрирует понятие Гнезда, Ядра и Нити, так как это определяется в документации SLURM.