Вхід
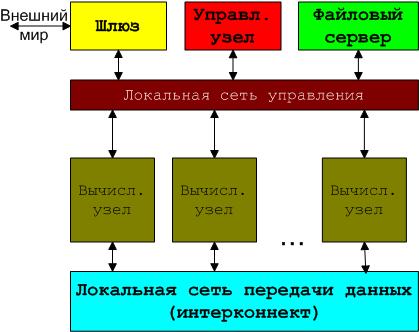
Архітектура комплексу СКІТ
Суперкомп'ютер кластерного типу являє собою масив обчислювальних вузлів, кожний з яких є багатопроцесорним сервером із симетричною багатопроцесорністю та масивом спільної оперативної пам'яті (SMP-архітектура), об'єднаних декількома локальними обчислювальними мережами різного призначення і продуктивності; з масиву обчислювальних вузлів можуть бути виділені керівні вузли для централізованого керування процесом обчислень, крім того, до складу суперкомп'ютера входять сервери, спеціалізовані на керування загальними файловими ресурсами (файловий сервер) і зовнішній доступ користувачів до кластера (сервер доступу).
Крім того в кластерному комплексі можуть бути один чи більше виділених вузлів компіляції, що у невеликих комплексах сполучені з керівними вузлами.
Загальна структура кластера
Кластерний комплекс складається з декількох суперкомп'ютерів кластерного типу, зв'язаних між собою глобальною файловою системою і мережами керування.
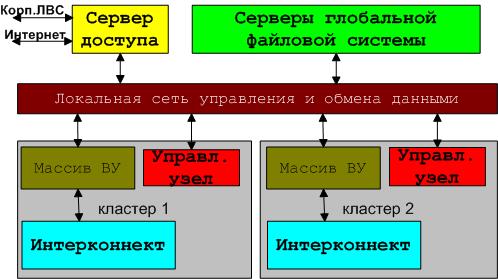
Загальна структура кластерного комплексу
Архітектурні компоненти кластерного комплексу
Архітектура мульти-серверної, кластерної системи - це багатопланова комбінація апаратно-програмних засобів, у тому числі на рівні взаємодії операційних систем серверів, розподілу обчислювальних процесів по процесорах і синхронізація цих процесів, ефективне обслуговування запитів до централізованих чи розподілених файлових систем.
Мережі керування й обміну даними. Ці мережі в кластерному комплексі звичайно зв'язують між собою керівні сервери і масиви обчислювальних вузлів. Мережа обміну даними (МОД) надає можливості:
- віддаленого вмикання-вимикання обчислювального вузла;
- доступу вузла до даних про мережну конфігурацію (протоколи DHCP, DNS);
- завантаження операційної системи в обчислювальний вузол (протоколи TFTP);
- доступу вузла до кореневої файлової системи (протоколи NFS, у майбутньому LUSTRE);
- постачання в обчислювальний вузол даних задачі (протоколи LUSTRE).
Мережа керування (МК) забезпечує можливість доступу до вузла ззовні для:
- оперативного керування вузлом;
- одержання статистичних даних по навантаженню процесорів, зайнятості пам'яті, показання датчиків температури, швидкості обертання вентиляторів;
- запуску і подальшого контролю процесів задачі.
При створенні кластерів СКІТ планувалося використання обох мереж -- мережі обміну даними на інтерфейсі Gigabit Ethernet (1000 Mbps) і керованому мережному устаткуванні і мережі керування на інтерфейсі Fast Ethernet (100 Mbps) і некерованому мережному устаткуванні, що дозволяє відокремити операції по роботі з файловою системою від керування вузлами навіть при повній завантаженості мережі.
Однак у ході експлуатації кластерів виявилося, що при максимально досяжному завантаженні мережі обміну даними стовідсоткова утилізація мережних інтерфейсів не досягається, залишається запас по пропускній здатності, достатній для функціонування мережі керування. Тому в кінцевому варіанті реалізоване повне відмовлення від виділеної мережі керування, а функції мереж обміну даними і керування об'єднані.
IP-мережа
У якості опорної в кластерах використовується IP-мережа, для якої з усіх приватних діапазонів IP-адрес (10.Х.Х.Х, чи 172.16.0.0 - 172.31.255.255 чи 192.168.Х.Х) був обраний діапазон 10.Х.Х.Х як найбільш просторий, а діапазон 172.16.Х.Х використовується в обмеженому обсязі для службової мережі.
У першому з обраних діапазонів застосована наступна схема розподілу підмереж IP-адрес:
- Обчислювальний вузол має IP-адреса 10.C.S.P, де C - номер кластера (ClusterNumber), S - номер комутатора (SwitchNumber), P - номер порту в комутаторі (PortNumber). Таким чином, 10.1.1.1 - це перший вузол першого кластера, 10.3.1.24 - двадцять четвертий вузол третього кластера.
- Маска IP-адреси = 255.0.0.0, тобто вся мережна інфраструктура цілком досяжна з будь-якого зміста мережі, при цьому розмежування різних кластерів виконується за допомогою VLАN'ов. У результаті вузли різних кластерів взаємно невидимі, при цьому системи збереження даних будуть доступні навіть у випадку, якщо функції системи збереження даних і керівного вузла кластера покладені на один пристрій.
- Керівний вузол кластера має фіксована IP-адреса: 10.C.S.254, де C - номер кластера, S - номер комутатора.
- Підмережа 10.0.0.0/16 віддана для сервісних служб, так, 10.0.0.254 - це сервер доступу, 10.0.0.252 - сервер метаданих, 10.0.0.{10-40} - пристрою безперебійного харчування і т.д. Надалі в цієї підмережі будуть знаходитися усі виділені фізичні сервери системи збереження даних, наприклад, по адресах 10.0.0.{240-247}.
- Комутатори мережі керування кластера мають фіксовану IP-адресу: 10.0.0.1CS, де C - номер кластера, S - номер комутатора.
Для більш спрощеного найменування вузлів кластера використовується DNS сервер з наступною схемою найменування: nXXX.cNN.icyb, де XXX - номер вузла в кластері, NN - номер кластера. Таким чином, вузли кластера СКІТ-2 мають імена n001.c03.icyb - n032.c03.icyb, а ім'я керівного сервера цього кластера - n000.c03.icyb.
Другий діапазон IP-адрес обслуговує підключення зовнішніх користувачів і всі комп'ютери, підключені до внутрішньокластерної мережі керування (комп'ютери адміністраторів), наприклад, 172.16.1.{11,22,33} - комп'ютери admin {1|2|3}, 172.16.1.44 - вихідний комутатор корпоративної ЛВС ИК, 172.16.1.66 - вихідний комутатор однієї з ЛВС Інституту космічних досліджень і т.д.
Система збереження даних (СЗД)
Як правило, паралельні задачі орієнтовані на обчислення, що зв'язані з гігабайтними масивами даних. Тому при побудові кластера зі збалансованими характеристиками украй важлива задача - надати вузлам при виконанні задачі високошвидкісний доступ до систем збереження даних великих розмірів.
Спочатку у якості системи збереження даних використовувалися керівні вузли двох кластерів з дисками, які були підключені до них. Для збільшення пропускної здатності системи збереження даних обрана функція PORT TRUNKING - об'єднання декількох (2-8) мережних інтерфейсів в один c збільшенням загальної пропускної здатності отриманого інтерфейсу, хоча лінійного приросту одержати не удалося.
При використанні звичайного транкінгу IP-стек OS Linux має недоліки при обробці великих пакетів, їхній дефрагментації при відправленні-прийомі через кілька інтерфейсів, що може приводити до втрат пакетів до 30%, помилкам на інтерфейсах і, як результат, до меншого очікуваного приросту. Варіантів рішення проблеми два: скористатися протоколом для транкінга 802.3ad за підтримкою його устаткуванням і/чи скористатися функціональністю JUMBO FRAMES.
Перший варіант СЗД
СЗД на СКІТ-1, 2 мала обсяг 0.4 Tбайт, створених на 4 SCSI-дисках у RAID5 з максимальною швидкістю лінійного читання і запису в 80 Мбайт/с. СЗД на СКІТ-2 мала обсяг 0.8 Tбайт, створений на двох двоканальных апаратних контролерах і 26 SCSI-дисках у RAID50, з передачею даних по чотирьох мережних інтерфейсах з максимальною лінійною швидкістю читання-запису в 330 Мбайт/с.
При розробці кластерів як початковий варіант розподіленої файлової системи розглядалася NFS. Вузли кластера не мають власних дисків, тому кожен вузол під час початкового завантаження монтує кореневу файлову систему по NFS. Також по NFS монтувалися і розділи з робочими даними задач. Вибір NFS був визначений декількома причинами -- це стандартна мережна файлова система, NFS мається в будь-якій UNIX-системі, NFS дуже легко набудовується і конфігурується.
Досвід експлуатації NFS у якості основної файлової системи показав, що NFS може бути непоганим вибором за умови використання для рахунка задач з невеликою кількістю операцій уведення-виводу з дисковими файлами. Однак NFS стає неприйнятним вибором при рішенні задач з інтенсивним уведенням-виводом. Тому файловий сервіс був істотно модернізований, і основними задачами модернізації були:
- вибір найбільш оптимальної розподіленої файлової системи з можливістю масштабування як за об'ємом з можливість об'єднати існуючі СЗД різних кластерів в одній загальну СЗД, так і за максимальною пропускною здатністю;
- перехід з повсюдного використання NFS на часткове чи повне використання обраної файлової системи.
У якості базової глобальної файлової системи за результатами аналізу існуючих глобальних файлових систем була обрана Lustre, глобальна файлова система, що інтенсивно розвивається по дуже багатьом параметрам відповідає умовам експлуатації кластерного комплексу СКІТ.
Організація глобальної файлової структури Lustre кластерного комплексу СКІТ була визначена як сполучення з декількох серверів, спеціалізованих на реалізацію функціональних серверів Lustre - сервера метаданих із двома дисками в RAID1, і серверів збереження даних з дисковими масивами в RAID5, об'єднаних одноканальною гігабітною мережею обміну даних (максимальна пропускна здатність 125 MБ/c), причому виділеним фізичним сервером є тільки сервер метаданих, а функції серверів збереження даних виконуються фізичними керівними серверами.
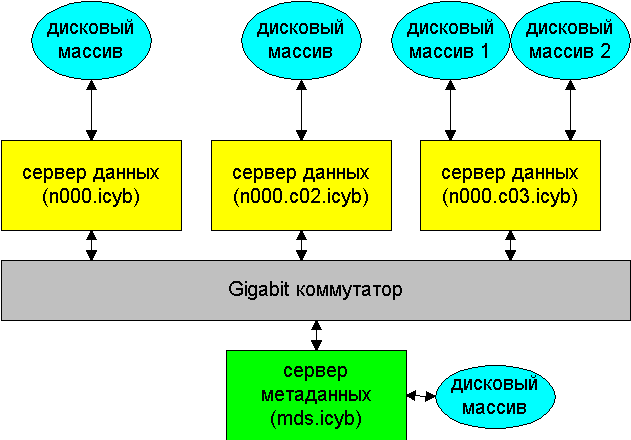
Структура СЗД без виділених серверів збереження даних
Дискові масиви керуються двома програмними RAID-контролерами (сервери n000.icyb і mds.icyb) і трьома апаратними RAID-контролерами (сервери n000.c02.icyb і n000.c03.icyb).
Прийнята схема глобальної файлової системи Lustre забезпечує:
- масштабованість за об'ємом (можна нарощувати число дисків у дискових масивах і число серверів збереження даних);
- масштабованість за пропускною здатністю за рахунок того, що пропускна здатність у цілому є сума пропускних здатностей кожної з компонентів (серверів збереження даних).
Практично вся робота з файлового вводу-виводу здійснюється по мережі обміну даними, тому вимоги до пропускної здатності цієї мережі дуже високі. Слід уточнити, що «вузьким місцем» у цій схемі є мережний інтерфейс сервера, пропускної здатності мережного інтерфейсу вузла вистачає з надлишком.
Пропускна здатність СЗД істотно збільшується з переходом до керування по двох гігабітних каналах (до 250 МБ/c на сервер даних), використанню виділених серверів збереження даних (OSS{0-1,4-5}.icyb) з дисками в RAID1, крім того, уводиться невиділений сервер резервного збереження даних (n000.icyb), що збільшує, у загальному випадку, надійність роботи СЗД.
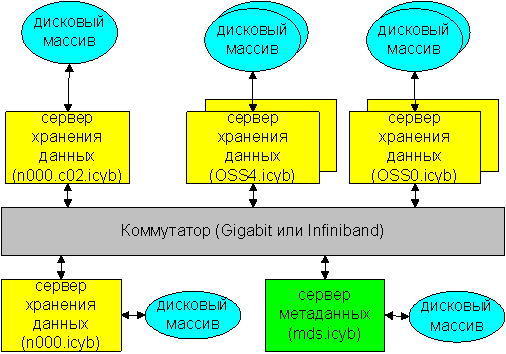
Структура СЗД c різними типами серверами збереження даних
Дискові масиви і продуктивність СЗД. Оскільки файлова система розподіляється по декількох фізичних серверах, то вимоги до надійності цих серверів і використовуваних ними дискових масивів досить високі. Припустимими по надійності є масиви рівнів RAID1, RAID5 і RAID6, RAID10.
Вибір конкретного рівня RAID визначається необхідною загальною продуктивністю файлової системи і пропускною здатністю використовуваних інтерфейсів.
RAID5 і RAID6 серйозно програють RAID1 і RAID10, до того ж RAID5 і RAID6 дуже погано переносять читання/запис невеликими порціями даних випадковим образом - у цьому випадку продуктивність може упасти в два-три разів.
RAID10 програє по продуктивності RAID1 по двох причинах:
- Немає абсолютно однакових дисків, різниця в продуктивності двох дисків навіть у межах однієї партії може доходити до 20%, тобто для усього RAID10 значення Pr і Pw упадуть на ці 20%, при використанні декількох RAID1 продуктивність упаде тільки для одного масиву
- Читання-запис у RAID10 торкаються абсолютно всі диски масиву, а отже, множинні запити на читання-запис будуть серйозно блокувати систему введення-виводу; практичне використання RAID1 і RAID10 свідчить про набагато більш високу масштабованість по навантаженню в RAID1.
Тому при використанні програмного RAID кращим варіантом для дискового масиву варто вважати варіант із використанням RAID1. Мінусом для RAID1 і RAID10 можна вважати дворазове зменшення ємності масиву в порівнянні з RAID5, але при нинішній вартості і ємності дисків цей мінус можна вважати несуттєвим. А до плюсів потрібно віднести неперевершену надійність RAID1 - так зруйнований масив на дисках ємністю 500GB відновлюється протягом 70 хвилин при відсутності зовнішніх запитів на читання-запис, тобто тільки в цей час єризик утратити дані, для масивів з іншими рівнями RAID цей час може доходити до декількох діб і з ростом ємності дисків тільки збільшується.
При використанні апаратного RAID-контролера ці правила теж справедливі, однак для одержання точних значень потрібні тестові іспити продуктивності конкретного контролера.
Іншим фактором, що впливає на вибір рівня RAID, є пропускна здатність використовуваного мережного інтерфейсу. Так, пропускна здатність GigE обмежена 125 MB/s, отже, використання RAID1 може виявитися просто неефективним і тільки приведе до втрати дискового простору в порівнянні з RAID5.
Наступний приклад пояснює сказане. При використанні 6 дисків по 250 GB кожний реальні виміри дають значення пікової продуктивності:
[RAID1] PFw = 210 MB/s та PFr = 420 MB/s;
[RAID5] PFw = 160 MB/s та PFr = 240 MB/s.
Таким чином, при використанні для доступу до дискового масиву тільки одного каналу GigE продуктивність RAID1 явно надлишкова і може бути реалізована при більшій кількості GigE, або при використанні більш продуктивного інтерфейсу типу Infiniband. У теж час, з урахуванням деякої втрати продуктивності в RAID5 при випадковому доступі до даних максимальна продуктивність RAID5 досягається вже з одним GigE, при цьому ефективна ємність дискового масиву в RAID1 буде дорівнює 750 GB проти 1250 GB у RAID5.
Обладнання серверів метаданих і даних
Файлова система Lustre має наступні архітектурні особливості: розмір сторінки пам'яті на серверах повинне бути не більше, ніж розмір сторінки пам'яті в клієнтів, а це означає, що використання в серверах архітектури IA64, у якої найбільша продуктивність досягається при розмірі сторінки в 16k і 64k, є неефективним тоді як ефективним буде застосування архітектур AMD64 чи EM64T, у яких розмір сторінки пам'яті дорівнює 4k і цілком відповідає архітектурі IA32.
У реалізації EM64T від Intel відсутній механізм IOMMU, що приводить до проблем при використанні більш 3 GB оперативної пам'яті й устаткування, якому необхідний доступ до верхніх сторінок пам'яті (контролери дисків відносяться саме до цього устаткування).
Коефіцієнт утилізації устаткування в 64-х бітному режимі істотно вище в порівнянні з 32-х бітним режимом, що дозволяє одержати більш високу продуктивність на тому самому устаткуванні.
Як результат, кращим вибором для серверів метаданих і даних є AMD64 архітектура. Застосування архітектури EM64T припустимо з деякими обмеженнями (менше 3 GB оперативної пам'яті і можливе відмовлення від використання EM64T на сервері метаданих при використанні процесорів 51xx) і втратою в продуктивності.
Тестові іспити продуктивності Lustre показують, що вимоги до процесора й обсягу оперативної пам'яті сервера метаданих мінімальні - цілком достатньо одноядрового 64-х бітного процесора з частотою більше 1.2 ГГц і не менш 512 МБ оперативної пам'яті, велика продуктивність потрібна тільки при кількості клієнтів і серверів даних, що обчислюється сотнями.
Тестові виміри продуктивності SoftRAID показують, що використання апаратних RAID-контролерів не є необхідною умовою для побудови паралельної файлової системи.
SoftRAID є нормальним вибором для реалізації RAID при наявності кваліфікованих адміністраторів і дозволяє уникнути серйозного подорожчання всієї системи. Використання апаратних контролерів необхідно тільки у випадку використання серверів даних з кількістю дисків, що перевищують кількість портів для підключення дисків.
Використання SCSI-дисків для побудови системи збереження даних не має раціонального обґрунтування. Як відомо глобальна продуктивність паралельної файлової системи досягається за рахунок великої кількості фізичних дисків, при цьому SATA-II диски підключаються кожний до свого виділеного каналу і не мають обмеження по пропускній здатності, тоді як SCSI диски підключаються до одного каналу, що має кінцеву продуктивність, і при великому навантаженні починають блокувати канал.
До того ж, ціна SCSI рішень у кілька разів перевищує SATA-II рішення. SAS диски, хоча і не мають обмеження по каналі - вони підключаються так само, як і SATA-II диски, але мають ціну, порівнянну з SCSI рішенням, тому використання SAS дисків також надмірно за бюджетом.
Мінімальні значення частоти процесора й обсягу оперативної пам'яті для сервера даних можна грубо оцінити в такий спосіб: 600 МГц плюс 200 МГц на кожен програмний RAID1, 400МГц на кожен програмний RAID1 і 200 МБ плюс 1 ГБ оперативної пам'яті на кожен терабайт керованого дискового масиву даних.
Бездискова ініціалізація обчислювальних вузлів
Кластерна організація масиву обчислювальний вузлів припускає як обов'язкову властивість ідентичність кореневої файлової структури всіх компонентів цього масиву. Кореневі файлові системи усіх вузлів ідентичні, за винятком декількох каталогів, що дійсно повинні бути в кожного унікальні.
Досягти виконання цієї властивості можна декількома шляхами - або копіюванням кореневої файлової структури в локальну дискову пам'ять кожного вузла, або використанням існуючих засобів ініціалізації серверів через мережний інтерфейс, поза залежністю від наявності локальної дискової пам'яті. У кластерному комплексі СКІТ застосовується другий підхід.
Кожен обчислювальний вузол налаштований на включення при одержанні мережним інтерфейсом спеціального пакета wake-on-lan і на завантаження через мережний інтерфейс по протоколі PXE. Керівний вузол відправляє сформований пакет через мережу обміну даними, і вузол ініціює процес завантаження. Вузли кластера СКІТ-2 налаштовані на вмикання-вимикання за допомогою протоколу IPMI, вузли якого апаратно підтримують цей протокол.
Обчислювальний вузол відправляє широкомовний запит і від сервера DHCP, що встановлений на керівному вузлі, одержує всю необхідну для завантаження системи інформацію, завантажує ядро і мінімальну кореневу файлову систему із сервера TFTP, що також установлений на керівному вузлі, розпаковує ядро і передає йому виконання.
Далі процес ініціалізації системи, базуючись на отриману по DHCP інформацію, монтує по NFS файлову систему, розташовану на СЗД, робить її кореневою і завершує ініціалізацію, передавши керування стартовим скріптам, розташованим на новій кореневій файловій системі. З цього моменту завантаження системи по чи мережі з локального диска практично не відрізняються. Надалі монтуються додаткові розділи NFS з робочими даними, користувальницькими каталогами і т.д. по необхідності.
Така схема, яка припускає, що коренева файлова системи у всіх вузлів кластера та сама, істотно полегшує адміністрування, відновлення, установку нового програмного забезпечення, оскільки працює з усім кластером цілком, і на порядки знижує можливість зробити помилку.
Віддалений моніторинг обчислювальних вузлів
Для оперативного контролю за станом запущеної задачі, її примусового завершення і звільнення зайнятих задачею ресурсів звичайно використовується доступ до вузла по протоколу SSH. Це має на увазі, що вузол повинний бути доступний.
Однак необхідність у базовому вилученому керуванні кожним вузлом кластера окремо, можливість виконання таких операцій як умикання-вимикання вузла, консоль з висновком завантаження призвело до встановлення мережі ServNET. Надалі планується використовувати вузли тільки з підтримкою стандарту IPMI версії вище 1.5, що забезпечує вилучене умикання-вимикання вузла при наявності тільки підключеного до вузла Ethernet кабелю і живлення, а функція Serial-over-LAN у IPMI 2.0+ дозволяє навіть віддалено налаштовувати BIOS вузла.
Система резервованого збереження даних
Необхідність у реалізації такої функціональності визначається тим, що дані в СЗД можуть бути загублені з багатьох причин. Це може статися в результаті помилки виконавця, збою контролера, виходу з ладу диска чи в результаті ще декількох десятків причин.
Дані, що можуть бути загублені на СЗД обчислювального комплексу - це дані десятків користувачів, це результати обчислень, що проходили протягом від декількох тижнів до декількох місяців, це вихідні тексти програмного забезпечення, частина якого може бути просто унікальна. Тому створення системи резервного копіювання для мінімізації можливих утрат украй необхідна. Проблем і обмежень при побудові системи резервованого збереження даних для комплекса СКІТ декілька:
СЗД на даний момент має розмір у 32TB, а в найближчий час вона буде розширена до 120 TB. Навіть якщо обмежити повне максимальне завантаження на рівні 70%, те необхідно забезпечити резервування даних у розмірі до 100 TB.
У СЗД використовується паралельна файлова система LUSTRE, тобто дані фізично «розмазані» по декількох серверах, тобто резервування даних може відбуватися тільки на логічному рівні - рівні доступу до файлової системи.
Використання в СЗД паралельної файлової системи має на увазі використання декількох фізичних серверів у якості одного віртуального, а отже, вихід з ладу кожного з модулів СЗД може привести до часткового чи повного руйнування СЗД.
Водночас із СЗД працюють кластери, що включають у цілому 125 обчислювальних вузлів, у режимі 24x7x365, тобто дані на СЗД постійно міняються, отже, не можна виділити окремий час для резервування незмінених даних.
Резервування даних у будь-якому випадку не повинне викликати падіння продуктивності СЗД, тобто повинне проходити як фонове.
У випадку руйнування даних на СЗД, відновлення до працездатного стану повинне вироблятися в мінімальний термін.
Варіанти прийнятних рішень:
- При побудові СЗД використовувати максимально можливу при невисокому бюджеті захищену від збоїв конфігурацію. Використання дискових масивів у RAID-5, RAID-6 чи RAID-1 дозволить захиститися від виходу з ладу жорсткого диска, а використання двох блоків живлення захистить від виходу з ладу одного блоку живлення. Однак відмовлення будь-якого іншого елемента, типу оперативної пам'яті, чи процесора контролера, або одночасне відмовлення декількох жорстких дисків, блоків живлення все рівно може привести до повної чи часткової втрати даних, а значить відмовостійкість цього варіанта хоча і висока, але не 100%. Проте, використання надлишкових RAID-масивів і надлишкових блоків живлення стає обов'язковою вимогою при побудові СХД для усіх використовуваних модулів.
- Мультисерверний файловий RAID-1 чи RAID-5. Ця властивість паралельної файлової системи LUSTRE дозволяє збільшити загальну відмовостійкість усіх або критично важливої частини даних СЗД.
- Відзеркалювання всіх даних на окремий сервер. Цей варіант не можна використовувати з кількох причин: Досить часто завантаження СЗД наближається до максимального, отже між СЗД і окремим сервером необхідно організувати канал величезної пропускної здатності і низкою латентності, у противному випадку продуктивність СЗД упаде в рази. Тобто виконання цього пункту вимагає істотного збільшення бюджету, що нереально. Окремий сервер повинний мати ємність дискових масивів не меншу, чим у СЗД, оскільки LUSTRE допускає нарощування по обсязі, то виконання цього пункту приводить до використання як окремий сервер повного аналога СЗД із подвоєнням бюджету на реалізацію.
- Структура з мінімізованим часом чекання доступу (HA-структура). У парі з варіантом 3 може дати рівень відмовостійкості СЗД близький до 100\%.
- Інкрементальне резервування. У даний момент ця технологія в її початковому вигляді взагалі не може бути використана з LUSTRE, оскільки має на увазі незмінні дані в період резервування, інакше буде порушена цілісність даних у резервній копії. Для активно змінюваних даних цілісність може бути забезпечена тільки при використанні можливості snapshots -- тобто можливість при який файлова система як би заморожується, виходить її знімок, а всі нові записи відбуваються в окреме сховище і не видимі на знімку, і цей знімок уже можна резервувати. Перешкодою для використання цієї технології є дуже великий період часу, затрачуваного на відновлення працездатності СЗД.
- Інкрементальне резервування частини даних. Навіть при загальному високому завантаженні забезпечити цілісність тільки частини даних не представляється чимось надприроднім. Приміром, користувальницький каталог залишається недоторкаємим поки в системі не зареєстрований власник каталогу, а отже, момент виходу користувача із системи є непоганою крапкою запуску резервного копіювання даних користувача.
Як видно, виділяється два підходи до резервного збереження даних:
- створення повної копії даних (1-4 варіанти);
- створення однієї чи декількох копій критично важливих даних (5-6 варіанти).
Однак самостійно жоден з підходів і жоден з варіантів не дає необхідного ступеня відмовостійкості. Так застосувавши для створення СЗД варіанти 1-4 і одержавши рівень відмовостійкості файлової системи 99.999 за рахунок двох- і триразового дублювання ключових елементів і за просто непристойно великий бюджет, усе рівно не можна гарантувати цілісність даних - будь-яка помилка в програмі, чи в діях кінцевого користувача може знищити чи частину навіть усі дані, чи просто їх зіпсувати, і все це може відбутися на тлі гарантованої цілісності файлової системи. У теж час, якщо піти по шляху 5-го варіанта й одержати трохи «знімків» файлової системи і навіть декількох версій того самого файлу, при апаратному збої на СЗД обсягом 100-200 TB відновлення файлової системи може зайняти 2-3 тижня.
Тому задача резервного копіювання даних повинна розглядатися тільки як підзадача створення всієї СЗД. Вирвана з контексту створення СЗД, задача резервування даних принесе тільки шкоду.
Результуючі вимоги, що визначають кінцеве рішення в СЗД:
- Необхідний рівень відмова-стійкості файлової системи;
- Необхідний рівень продуктивності;
- Мінімальний час простою системи при відновленні;
- Максимальний обсяг СЗД;
- Максимальний обсяг даних для резервування;
- Бюджет проекту.
Ступінь задоволення цих вимог, чи цілком часткове, визначає стратегію резервування і вимоги до самої системи резервованого збереження даних.
Структурна блок-схема кластерного комплексу
Експлуатація суперкомп'ютерної обчислювальної техніки пов'язана зі значними незручностями у роботі людей в обчислювальних залах, де вона знаходиться, - велике енергоспоживання і, відповідно, локальна генерація значної кількості тепла у шафах електроніки вимагають апаратних засобів відведення цього тепла. Останні практично виключно ґрунтуються на відводі тепла із шаф десятками і сотнями вентиляторів, створюють значний звуковий дискомфорт для людей, які перебувають поруч із цими шафами. Крім того, якщо для людини комфортною температурою в обчислювальному залі є діапазон 18-22С, то для апаратури найкращим температурним діапазоном є 10-16С.
Поділ зони розташування шаф обчислювального комплексу та зон роботи інженерів і системних програмістів -- природно, а, отже, дистанційне управління обчислювальним комплексом, безперервний моніторинг функціонування його апаратури, інфраструктури і програмного забезпечення, створення засобів безперервного віддаленого управління потоком завдань на у кластерному комплексі - все це обов'язкові функціональні компоненти працюючого цілодобово обчислювального комплексу.
Кластерний комплекс ІК НАН України функціонує в умовах нестабільного зовнішнього електроживлення, і наявність резервного електроживлення не передбачалася з фінансових міркувань. Тому вся апаратура поділяється на 2 частини:
- Апаратні засоби, які не повинні відключатися, як мінімум, протягом десятків хвилин відсутності зовнішнього живлення. Енергоспоживання цих засобів має бути мінімальним, в іншому разі частка засобів безперебійного живлення буде неприпустимо висока як за вкладеними в них фінансовими ресурсами, так і за реальними розмірами.
- Апаратні засоби, які можуть бути відключені як при короткочасних зникненнях зовнішньої напруги, так і за рішенням адміністратора комплексу. Зазвичай енергоспоживання цих засобів у багато разів більше енергоспоживання апаратних засобів 1 групи.
Цей підхід відобразився у структурі - були виділені першу групу всі управляючі сервери, мережеві комутатори та система зберігання даних - тим самим забезпечується мережеве управління всіма компонентами кластерного комплексу за IP-адресами і доступ до даних на дискових RAID-масивах. У другу групу віднесено всі обчислювальні вузли і інтерконект, причому в кожен сервер обчислювального вузла вводиться додатковий апаратно-програмний засіб, який дозволяє віддалено включати -- виключати, налаштовувати і контролювати кожен обчислювальний вузол індивідуально.
До складу програмного забезпечення кластерного комплексу включено засоби постійного моніторингу, які починають працювати в регламентному режимі відразу після включення управляючих серверів і які не створюють істотного навантаження як на управляючі сервери, так і на обчислювальні вузли. Спрощена блок-схема організації кластерного комплексу, розрахованої на цілодобову експлуатацію і мережеве управління, показана нижче:
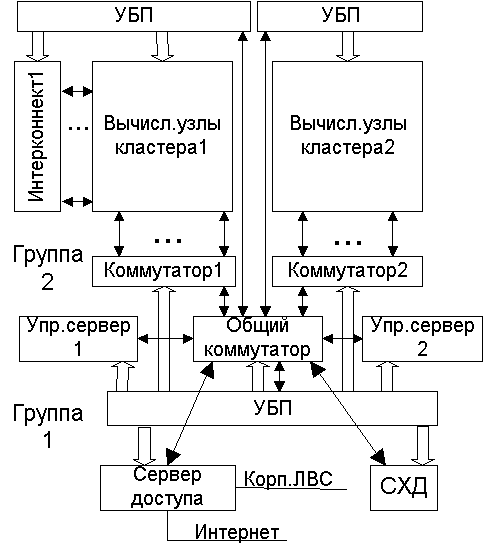
Блок-схема кластерного комплексу
На рис. група 1 - пристрої, виділені в групу пристроїв з постійним електроживленням, вони забезпечують віддалений доступ до всіх компонент кластерного комплексу. У групу 1 входять:
- управляючі сервери 1 і 2 кластерів,
- сервер доступу,
- комутатори мережі управління 1 і 2 кластерів,
- загальний комутатор кластерного комплексу,
- система зберігання даних (СЗД, СХД),
- пристрій безперебійного живлення (ПБЖ, УБП) на 5 кВт.
Група 2 містить пристрої з великим електроспоживанням і функціонально необхідні лише за їхню роботу.
У групу 2 входять:
- обчислювальні вузли 1 і 2 кластерів,
- комутатор інтерконекта для кластера 1 (на InfiniBand),
- комутатори мережі моніторингу на основі Fast Ethernet,
- ПБЖ по 10 кВт на кожну шафу.
Зв'язки інфраструктури кластерного комплексу по електроживленню показані як однонаправлені (від ПБЖ до пристрою-споживача) широкі стрілки, зв'язки по IP-адресами, а ця адресація охоплює всі пристрої кластерного комплексу, показана як двонаправлені стрілки чи стрілки без вказівки напряму.
Загальний комутатор у групі 1 необхідний з двох причин:
- Через нього підключається оптоволоконний кабель, який з'єднує обчислювальний зал, де розміщується кластерний комплекс, з приміщенням, де знаходяться дисплеї адміністраторів комплексу і звідки він управляється і контролюється;
- Для балансування пропускної передачі протоколами NFS між компонентами комплексу, що виконується створенням віртуальних підмереж і організацією транкових передач між ними.
Оцінка мінімальної потреби в групах віртуальних мереж і кількості портів для транкового зв'язку така:
- по одному 4-портовому транку до коммутаторів управління кластерів;
- 4-портовий транк до схеми зберігання даних і управляючого серверу СЗД (він же управляючий сервер кластера 3);
- усі пристрої безперебійного живлення ПБЖ підключаються до загального комутатора, займаючи по 1 порту (всього 4 порти), по 1 порту займають зв'язки з управляючим сервером 1 кластеру, сервером доступу, ще 1 порт GBIC необхідний для підключення трансивера - конвертора оптоволокно - мідь, всього мінімальна потреба в портах загального комутатора становить 19 портів типу Gigabit Ethernet.
Інфраструктура електроживлення кластерів
Стабільне по параметрам електроживлення вузлів кластеру залежить багато в чому від навантаження ПБЖ який обслуговує шафу з обчислювальними вузлами.
Розрахункові характеристики для визначення навантаження на кожен канал ПБЖ для розподілу навантаження між ними такі:
- Кожен канал ПБЖ в режимі безупинної роботи може стабільно забезпечувати навантаження до 2,5 kVA, всього таких каналів в ПБЖ на 10 кВт чотири;
- Максимальне навантаження, створюване вузлом кластеру, залежить від типу процесора: 0,65 кВт для вузла на процесорі Xeon X4, 0,45 кВт для вузла на процесорі Xeon X2.
Звідси, у шафі СКІТ до кожного каналу ПБЖ можуть бути підключені по 6 обчислювальних вузлів, всього треба 4 канали, тобто один ПБЖ на 10 кВт (пікове споживання 2,7 кВт на канал, середнє не більше 2,3 кВт). У другому випадку до кожного каналу можуть бути підключені 4 вузла, всього треба 4 канали, тобто один ПБЖ на 10 кВт (пікове споживання 2,6 кВт на канал, середнє не більше 2,2 кВт).
За результатами експлуатації можна стверджувати, що інтенсивність завантаження кластеру завданнями з користувальницького програмного потоку набагато нижча інтенсивності завантаження в режимі випробувань по тесту Linpack за сумарною оцінкою - коефіцієнт використання процесора (0,97-0,99), помножений на коефіцієнт використання пам'яті (0,46 - 0,47). З цієї причини ПБЖ працює у режимі, близькому до критичного, лише при тестових випробуваннях під Linpack, в інших випадках його режим близький до рекомендованого виробником ПБЖ (не більше 0,75 максимальної навантаження).
Картина звичайного електроспоживання шаф кластерів відбувається наступним чином:
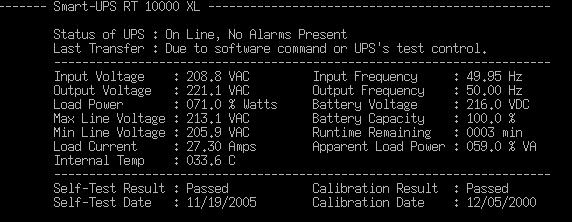
Середнє навантаження на ПБЖ шафи
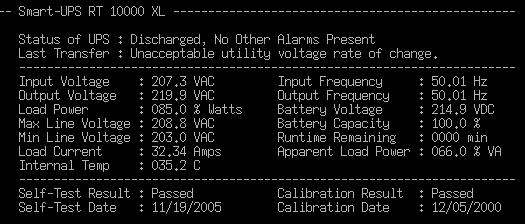
Максимальне навантаження на ПБЖ шафи
Користувачі в кластерному комплексі
Суперкомп'ютер кластерного типу являє собою обчислювальну систему з несиметрично. мультипроцесорністю і кешированням даних і задачі, що призначаються для виконання в такім обчислювальному середовищі, мають особливості:
- кожне завдання полягає з множини взаємодіючих процесів, що мають ідентичний код, вони запускаються на різних вузлах кластера і виконують кожний якусь частину загальної роботи;
- під час роботи процеси можуть інтенсивно обмінюватися даними між собою;
- міжпроцесорний обмін даними приводить до вирівнювання продуктивності кожного процесу по швидкості самого повільного;
- кожен процес, як правило, займає на час виконання великий обсяг оперативної пам'яті.
Кластерна задача розташовується в домашньому каталозі користувача і для виконання одержує на конкурентній основі два типи кластерних ресурсів - процесорний ресурс і часовий ресурс. Тривале безупинне рішення задачі сполучене з можливістю не одержати результати вчасно (наприклад, через збої при великому завантаженні іншими задачами), тому задачам надається подвійний часовий ресурс - як повний час рішення задачі, так і час сеансу - час безупинного рішення, після сеансу в задачі повинна формуватися контрольна крапка, що зберігає отриманий проміжний результат. Технологія програмування з контрольними крапками є одним з основних компонентів організації виконання задач, оскільки дозволяє багаторазово переривати виконання і відновляти його на проміжних результатах.
Керування користувачами через LDAP: 6 скріптів у СКЗ для роботи з даними з бази даних користувачів, що створюється при створенні облікового запису - реєстраційні дані, використовувані при роботі системних програм (uid, gid, login, password), довідкові дані користувача, у тому числі повне ПІБ, що представляється організація, тел., email), домашній каталог за адресою /home/users/, login, ключі, відкритий і закритий, для безпарольного доступу на вузли кластерів по ssh, каталог допомоги з документацією по роботі в кластерному оточенні і із СКЗ.
Компіляція і виконання задач
Для кластерного комплексу існують два реальних варіанти компіляції задач користувача: На керівному сервері, ніякі ресурси при цьому не вимагаються, робота виконується як попередня частина задачі, а обчислювальна потужність керівного сервера цілком достатня, щоб черга компіляції була порожня. Задача після успішної компіляції переміщається в ресурсну чергу на виконання, при помилках - закінчується.
На кожнім з обчислювальних вузлів кластера, зазначеного в паспорті задачі. У цьому випадку компіляція розглядається як звичайна задача, а недоліками є:
- необхідність одержати ресурси для початку компіляції і
- необхідність у додаткових діях користувача, щоб відправити задачу на виконання.
Задача, що знаходиться в ресурсній черзі й одержала їх, починає виконання у виді запуску стартового процесу на керівному сервері, що, у свою чергу, запускає обчислювальні процеси на виділених вузлах кластера. При цьому дотримуються прийняті для кластерного комплексу СКІТ властивості виконання задач:
- Безпарольний доступ (по відкритому rsa-ключу) на вузли кластера.
- Виконання задачі йде з експортованого на обчислювальний вузол домашнього каталогу користувача.
- Права задачі - права користувача.
Безпека кластерного комплексу
Мається два аспекти безпеки кластерного комплексу - по-перше, захист самого комплексу від несанкціонованого доступу (у тому числі і від зареєстрованих користувачів) і, по-друге, кожному з користувачів повинний бути гарантований індивідуальний захист його домашнього каталогу від інших користувачів.
Доступ користувачів у систему. Реєстрація користувача проводиться на LDAP-сервері і дані цієї реєстрації доступні по LDAP-протоколі в будь-якій крапці кластерного комплексу. Для збільшення відмовостійкості системи працюють два резервних LDAP-сервери.
Ззовні користувач може потрапити усередину кластера тільки через сервер доступу, пред'явивши криптографічний пароль, після перевірки йому відкривається вхід у домашній каталог. Останні розташовуються на сервері доступу, куди монтуються засобами глобальної файлової системи кластерного комплексу.
Захист користувачів заснований на використанні захищених протоколів для доступу до системи (SSH), криптостойких паролів входу в систему, rsa- чи dsa-ключів і застосуванні необхідних прав доступу і ACL (access control list) до користувальницьких каталогів і файлів. Для пересилання даних між користувальницьким комп'ютером і сервером доступу використовуються захищені протоколи SSH (команди scp, sftp).
Перспективним рішенням є переклад системи доступу користувачів і запуску задач на Web-інтерфейс, заснований на інтерфейсі HTTPS. Цей інтерфейс використовує шифрування за допомогою протоколів SSL (Secure Socket Layer), що забезпечує досить високий рівень захищеності каналу передачі даних між кластером і користувачем. Використовуючи HTTPS, можна об'єднати захищеність каналу і звичну для прикладного користувача середовище роботи з Web-платформою, що на сьогоднішній день вважається однієї з найбільш перспективних платформ.
Доступ до компонентів системи. Можливі кілька регламентів виконання користувальницьких задач:
- Зареєстрованому користувачу надається право доступу на всі обчислювальні вузли, виділені для задачі, після закінчення якої це право припиняє дія.
- Користувач передає свою задачу при старті в керування псевдокористувачу, а сам може тільки контролювати хід її виконання й одержувати результати, як проміжні, так і остаточні.
Раніше для кластерів СКІТ-1 і СКІТ-2 з розумінь безпеки, а також через різношерстість систем збереження даних, був обраний другий варіант, хоча він і зв'язаний з істотним обмеженням прав контролю поводження власної задачі на вузлах кластера з боку користувача.
Задача після перебування в ресурсній черзі та їхнього одержання переміщалася в робочий каталог (для кожної задачі індивідуальний) для виконання і виконувалася на виділених ресурсах кластера вже засобами системи керування задачами (СКЗ) і з правами одного з псевдокористувачів, а після виконання результати поверталися користувачу.
Недоліки цього підходу очевидні - зайве копіювання даних, що для деяких задач можуть бути дуже значні, утрата місця на системах збереження даних та інші. Результат боротьби з проблемами продуктивності “вилився” у використання технології Persistent Data (інструмент, що дозволяє користувачу заздалегідь помістити на постійне збереження великі масиви даних, рятуючи від тривалого копіювання при постановці задачі в чергу).
Після впровадження Lustre у якості основної файлової системи кластерів з розташуванням домашнього каталогу користувача на розподіленій файловій системі автоматично вирішилася і проблема копіювання великих масивів даних з користувальницького оточення в робочий каталог задачі. Тепер робочим каталогом задачі виступає стартовий каталог, заданий користувачем, а його задача одержує доступ до виділеним їй вузлам кластера з правами користувача, через його відкритий rsa-ключ. Але це рішення зажадало корінний переробки всієї системи керування чергами задач і зміни всіх підходів до безпеки виконання задачі, довелося відмовитися від використання псевдокористувачів і дати можливість виконуватися задачі з правами її власника. З одного боку, таке рішення значне спростило весь ланцюжок керування чергами задач, з іншого боку - система безпеки усе ще знаходиться в стані становлення.
Організація захисту кластерного комплексу. Захист має кілька рівнів. Перший рівень полягає у захисті від несанкціонованого доступу. Засобами такого захисту є фізичне відокремлення мережі комплексу, захист сервера доступу за допомогою фільтрації пакетів. Відкритими для доступа ззовні мають бути тільки порти ssh та http і https. Та мають бути докладені зусилля для захисту цих служб.
SSH є досить захищеним сервісом. Слабким місцем у нього є паролі користувачів. Ні в якому разі не можна дозволяти користувачам задавати прості паролі. Доброю профілактикою є періодична перевірка стійкості паролів користувачів програмою на зразок „John” із підключенням максимальної кількості словників. Також потрібно заборонити вхід користувача root на сервер доступу.
Другим вразливим місцем є сервер Apache. Потрібно відслідковувати інформацію про знайдені у ньому вразливості, своєчасно його оновлювати. Бажано відключити непотрібну функціональність.
Другим етапом є захист системи та конфіденційної інформації від зловмисних дій користувача, який вже знаходиться у кластерному комплексі. Цей етап значно складніший, оскільки вразливих місць і методів атаки набагато більше.
Оскільки у комплексі використовуються експериментальні драйвери, то цілком можливі помилки у ядрі ОС, які можуть бути використані для несанкціонованого доступу.
Наступним вразливим місцем є система керування задачами, оскільки вона працює із правами суперкористувача і обробляє запити користувачів. Тому мають бути перевірені на коректність всі місця, де приймається та обробляється інформація, отримана від користувачів.
Місцем потенційного інтересу є база користувачів, яка знаходиться у OpenLDAP. Доступ до неї має бути захищений паролем. Вразливим місцем є скрипти та веб-сервер Apache, які працюють із базою користувачів. Вони містять пароль до бази у відкритому вигляді. Файли, які містять пароль, мають бути обов'язково захищені від доступу будь-кого, крім суперкористувача.
Вразливим місцем є відкриті сокети систем, які не використовуються масово, а значить, гірше відтестовані і можуть мати вразливості. Такими є сервіси Lustre.
Місцем, де зберігається конфіденційна інформація, є ПК адміністраторів комплексу, вони повинні мати достатній рівень захисту.
Ще одним моментом є можливість перевантаження каналу Інтернет-користувачами, що може призвести до некерованості комплексу. Засобом проти цього є заборона з'єднання назовні з комплексу та введення квот.
Щоб уникнути доступу до файлів інших користувачів, маска створення файлів має бути umask 066.
Таке обладнання, як пристрої безперебійного живлення UPS, комутатори, керування засобами IPMI, мають бути захищені надійними паролями.
Аналіз продуктивності комплексу СКІТ
Вплив архітектурних рішень на реальну продуктивність
Специфічні властивості паралельної кластерної задачі:
- Задача - це множина процесів, які мають ідентичний код, які запущені на різних вузлах кластеру і які виконують частину загальної роботи.
- Під час роботи процеси можуть проводити інтенсивний обмін даними між собою.
- Міжпроцесовий обмін даними призводить до вирівнювання продуктивності кожного процесу за швидкістю самого повільного.
- Кожен процес, як правило, вимагає під час виконання велику кількість оперативної пам'яті.
Виходячи з цих властивостей, можна сформулювати загальні вимоги до вузла кластеру:
- Продуктивність вузла прямо залежить від потужності процесора.
- Міжпроцесорный обмін даними завжди швидше міжвузлового обміну, тобто, краще використовувати (2-4)-х процесорні вузли і двохядерні, а в недалекому майбутньому і чотирьохядерні процесори.
Продуктивність вузла прямо залежить від:
- частотних характеристик шини оперативної пам'яті;
- кількості доступної в вузлі оперативної пам'яті (до певної розумної межі);
- типу інтерконекта, який використовується, при цьому важливими є дві характеристики - латентність, тобто, затримка, яка виникає при передачі мінімального пакета між вузлами, і максимальна пропускна здатність;
- інтенсивності операцій вводу-виводу з пристроями зберігання даних.
Розглянемо детальніше вплив властивостей процесора і пам'яті.
Конвеєр і системні виклики. Як правило, паралельні завдання використовують класичний лінійний алгоритм, тому класична архітектура з коротким конвеєром, яка використовується в процесорах AMD, набагато краща архітектури P4 процесорів INTEL. Кожне звернення до даних сусіднього процесу супроводжується кількома переходами в привілейований режим процесора. Ціна цього переходу на процесорах AMD становіть 120-240 тактів, на процесорах архітектури P4 1100-1300 тактів.
HyperThreading. За рахунок простою одного з конвеєрів при невірно передбаченому переході чи просто неможливості паралельного виконання інструкції на архітектурі P4 є можливість використання вільних ресурсів як віртуального процесора (HyperThreading), але в паралельних завданнях це призводить тільки до падіння продуктивності. Причина проста - міжвузловий обмін вирівнює продуктивність всіх процесів за швидкістю самого повільного і, оскільки на віртуальний процесор доводиться не більше 40% реального процесора, то загальна продуктивність падає у 2-3 рази, тобто, цю можливість використовувати неможливо.
64 біта проти 32 бітів. На сьогодні всі процесори або підтримують 64-бітні розширення (AMD64, EM64T), або є чистими 64-бітними процесорами. На жаль, нині виграш від використання розрядності в 64 біта одержують лише програми, які використовують в обчисленнях довгу арифметику, та й то не завжди, інші лише програють (через збільшеного вдвічі розміру даних і адреси). Причин цьому кілька:
- Потрібно збільшити вдвічі кеши процесора, інакше спостерігається падіння продуктивності при частому вимивання кеша;
- При тій же ширині шини пам'яті потрібна вдвічі більша кількість звернень до оперативної пам'яті, що дає падіння продуктивності;
- Потрібне збільшення вдвічі оперативної пам'яті вузла.
Розсіювальна потужність процесора може неявно впливати на загальну продуктивність всієї системи - при перегріві одного з процесорів до нього буде застосовано автоматичне зниження частоти, що відразу ж призведе до загального падіння продуктивності всієї системи в цілому.
Оперативна пам'ять. Кластери мають 1-2 гігабайта пам'яті на кожне процесорне ядро вузла:
Більше 2 ГБайт на вузол доцільно мати або при використанні чистої 64-бітової архітектури, або після уточнення специфіки основних прикладних завдань кластеру, інакше пам'ять буде істотно простоювати.
Частота, на якій працює оперативна пам'ять, має бути максимальною з підтримуваних обраною архітектурою процесора.
Чіпсет повинен підтримувати необхідну кількість пам'яті (це стосується лише P4 від INTEL і чіпсета i945, де система не бачить більше 3.2 Гбайт).
Інтерконект. Оскільки ціна інтерконекту лежить в дуже широкому діапазоні від нуля до кількох тисяч доларів на вузол, то вибір інтерконекту визначається основним призначенням кластерної системи.
Латентність інтерконекта - один з найважливіших показників, що впливають на реальну продуктивність кластерної системи. Це час, витрачений операційною системою і пристроєм на передачу одного окремого пакета іншому вузлу кластеру. Оскільки міжвузловий обмін даними складається з таких передач, то латентність можна охарактеризувати як час, втрачений процесом. Для завдань з великим міжвузловим обміном велика латентність може дати катастрофічне падіння продуктивності, тоді ж як для грід-орієнтованих завдань з малим міжвузловим обміном мала латентність не дасть нічого в плані виграшу продуктивності, але призведе до величезного збільшення бюджету проекту.
Пропускна здатність інтерконекта практично не позначається на загальній продуктивності системи. Існують деякі мінімальні межі, але пропускна здатність будь-якого пристрою, який використовується сьогодні як інтерконекта, перебуває набагато вище цих меж.
Надійність сполучних кабелів неявно впливає на реальну продуктивність системи в цілому, оскільки може і призводить до серйозного збільшення латентності як на окремій ділянці, так і у всій системі.
Вибраний інтерконект має підтримувати заплановану кількість вузлів кластеру (наприклад, SCI обмежений 256 вузлами), інакше буде неможливий вихід на заплановану продуктивність чи істотне падіння реальної продуктивності у разі використання проміжного інтерконекта.
Продуктивність пакету Linpack
Суперкомп'ютери, у тому числі кластери, порівнюються між собою за результатами прогону пакета Linpack, а якість архітектури й організації обчислювального процесу в кластері оцінюється не тільки відношенню до максимально досяжної пікової продуктивності, але й в залежності від встановленого серверного устаткування та системного програмного забезпечення. Кожен прогін пакета Linpack на максимальних параметрах пов'язаний із значними часовими витратами. В пакеті прогін одного набору вхідних даних полягає в виконанні 18 тестів, кожен з яких може вимагати від десятків хвилин для невеликих матриць з порядком до 40000, так і до годин для матриць значно більшого розміру.
Завдяки розміщенню всіх вхідних даних в оперативній пам'яті суперкомп'ютера і виключення свопінгу даних з зовнішньої пам'яті цілком прийнятна технологія попереднього розрахунку профілю продуктивності на матрицях невеликого розміру для вибору локальних максимумів з наступним ретельним прогоном вже на цих максимумах. Грубе спрощення процедури розрахунку позначається, звісно, на отриманих результатах, але загальна картина є правильною, вона багато в чому визначається розміром NB пакета обміну, а також технологією інтерконекта.
Щодо впливу технології інтерконекта, можна констатувати стабільне значення вимірюваної продуктивності між тестами в рамках одного прогону для інтерконекта на InfiniBand'і і більш ніж 2% розкидом для інтерконекта на основі SCI. Проте, профілі продуктивності в різних технологіях добре корелюють один з одним.
Обладнання кластера СКІТ-3 було оновлено у 2008 році, додано ще 52 8-ми ядерних вузли із 16 Гб оперативної пам'яті.
Пікова продуктивність кластера СКІТ-3 7,35 ТФлопс, а продуктивність у тесті Linpack дорівнює 5,3 ТФлопс, що складає 0,72 від пікової продуктивності. Даний коефіцієнт не найвищий серед подібних систем. Це можна пояснити значною різницею у тактовій частоті процесорів першої та другої черги СКІТ-3 (3,0 ГГц та 2,3 ГГц).
При цьому чотириядерні процесори виявляються недовантаженими. Про це свідчить і той факт, що для першої черги СКІТ-3 частка реальної до теоретичної продуктивності складає 0,79, що є дуже хорошим показником серед систем на платформах такого типу.