Вхід
Інструкція Slurm для користувача. Короткий посібник по запуску
Проста Linux Утиліта для Управління Ресурсами (SLURM) - це відкрита, надійна та добре масштабована система управління ресурсами кластера з планувальником задач, яка застосовується як для великих, так і для малих Linux-кластерів.
Як менеджер ресурсів кластера, SLURM виконує три ключові функції.
По-перше, він визначає виділений та/або спільний доступ користувачів до ресурсів (обчислювальних вузлів) на деякий час для виконання ними обчислювальних задач.
По-друге, він забезпечує функціонування структури запуску, виконання та моніторингу задач (зазвичай це паралельні задачі) на виділених вузлах.
Нарешті, він розподіляє ресурси, керуючи чергою чекаючих запуску задач.
Архітектура
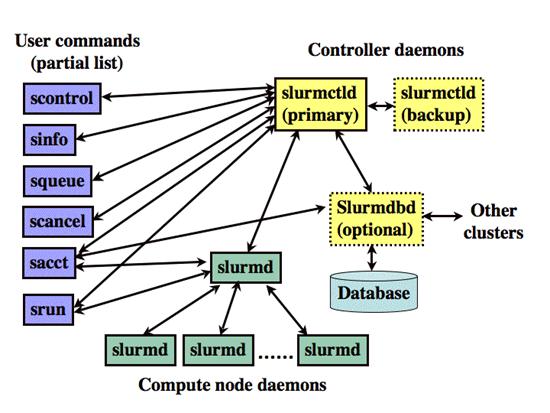
SLURM складається з сервіса slurmd, що запускається на кожному обчислювальному вузлі, та центрального сервіса slurmctld, що запускається на керівному вузлі (опціонально - з резервною копією керівного вузла).
Сервіси slurmd утворюють відмовостійку ієрархічну структуру. Користувацькі команди включають: sacct, salloc, sattach, sbatch, sbcast, scancel, scontrol, sinfo, smap, squeue, srun, strigger та sview. Всі ці команди можуть бути запущені як з керівного сервера, так і з вузлів кластера.
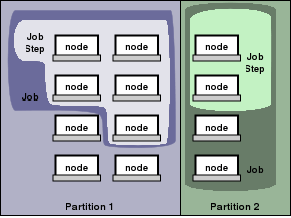
Об'єкти, керовані сервісами SLURM, це вузли - обчислювальний ресурс SLURM-а, розділи, що об'єднують вузли в логічні (можливо, які частково перекриваються) множини, задачі підмножини ресурсів, виділених користувачеві на вказану кількість часу, і кроки задачі, які є множинами (можливо паралельних) підзадач в рамках задачі.
Розділи можуть розглядатися як черги задач, кожна з яких має комплекс обмежень, як, наприклад, обмеження задачі за розміром, за часом виконання, рівнем доступу користувачів тощо. Задачі в черзі впорядковані за пріоритетом і їм виділяються ресурси у відповідному розділі.
Як тільки для задачі виділена множина вузлів, користувач може запускати паралельну роботу у вигляді кроків задачі в будь-якій конфігурації, в межах виділених вузлів.
Для прикладу, задача може бути запущена таким чином, що один єдиний її крок виконання займе всі виділені ресурси, в той же час кілька підзадач можуть незалежно одна від одної використати частину виділених ресурсів.
Команди
Довідкові man-посібники існують для всіх сервісів SLURM, команд, і API функцій. Параметр --help видає короткий перелік можливих параметрів команди. Зауважте, що параметри команд не залежать від регістру.
sacct використовується, щоб повідомляти задачі або підзадачі облікову інформацію про поточні або завершені задачі.
salloc використовується, щоб виділити ресурси для задачі в реальному часі. Зазвичай ця команда використовується, щоб отримати ресурси та shell-доступ до них. Потім використовується командний рядок, щоб виконувати srun-команди для запуску паралельних задач.
sattach використовується, щоб зв'язати потоки стандартного введення, виведення, помилок, передачу сигналів із запущеною задачею або підзадачею.
sbatch використовується, щоб запустити скрипт пакетної обробки для подальшого виконання. Скрипт зазвичай містить одну або більше srun-команд для запуску паралельних задач.
sbcast використовується, щоб перемістити файл з сервера запуску на обчислювальний вузол задачі. Це може бути використано, щоб ефективніше використовувати бездискові обчислювальні вузли або забезпечити поліпшену продуктивність загальної файлової системи.
scancel використовується, щоб скасувати випадково запущені або завислі задачі та підзадачі. Вона може також бути використана, щоб відправити керуючий сигнал всім процесам, пов'язаним з виконуваною задачею або підзадачею.
scontrol - інструмент адміністрування для перегляду та /або зміни стану SLURM. Відзначимо, що багато з керуючих команд можуть виконуються тільки суперкористувачем.
sinfo повідомляє стан розділів та вузлів, керованих SLURM. Вона має багато способів фільтрації, сортування, та форматування отриманих результатів.
smap надає графічну інформацію про стан задачі, розділів, та вузлів, керованих SLURM.
squeue доповідає про стан задач та підзадач. Вона має багато способів фільтрації, сортування, та форматування отриманих результатів. За замовчуванням, вона в першу чергу повідомляє про запущені задачі, завислі задачі йдуть наступними за ранжируванням.
srun використовується, щоб запустити задачу або підзадачу в реальному часі. srun має багато різних параметрів, щоб конкретизувати вимоги до ресурсів, у тому числі: мінімальна та максимальна кількість вузлів, кількість процесорів, вказати, які вузли використовувати або не використовувати, характеристики вузлів (скільки пам'яті, дискового простору, визначені необхідні особливості тощо). Задача може містити множину job кроків, що виконуються послідовно або паралельно на незалежних або загальних вузлах у межах виділених задачі вузлів.
strigger використовується для установки та перегляду тригерів подій. Тригери подій спрацьовують в таких випадках, як, наприклад , вихід з ладу вузлів або задач, що наближаються до їх межі часу.
sview - графічний інтерфейс користувача, що дозволяє отримати та оновити інформацію про стан задач, розділів та вузлів керованих SLURM.
Приклади
Для початку ми визначаємо, які розділи існують в системі, які вузли вони включають, і який стан системи в цілому. Ця інформація надається командою sinfo.
$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
scit1 up 44-10:40:0 24 down* n[1001-1024]
scit2 up 2-02:00:00 32 down* n[2001-2032]
scit3* up 20-20:00:0 8 drain* n[3015,3019,3035,3058,3063-3065,3146]
scit3* up 20-20:00:0 14 down* n[3007,3031,3043,3045-3046,3048,3073-3074]
scit3* up 20-20:00:0 1 drain n3006
scit3* up 20-20:00:0 72 alloc n[3008-3010,3012-3014,3016-3017]
scit3* up 20-20:00:0 3 idle n[3049,3135,3143]
scit3gpu up 44-10:40:0 4 idle gpu[1-4]
lite_task up 3:00:00 1 down* n3152
lite_task up 3:00:00 4 idle~ n[3026-3029]
Бачимо, що є шість розділів: scit1, scit2, scit3, scit3gpu, lite_task. Наявність * у назві розділу вказує, що це default розділ для запуску задач. Ми бачимо, що всі розділи перебувають у стані UP.
У кожному рядку наводиться інформація про максимальний час роботи задачі в розділі, кількість вузлів, їх стан та список вузлів. Так, у розділі scit3 8 вузлів на обслуговуванні та вимкнені (drain, *), 14 вимкнені (down; *), 1 в обслуговуванні (drain).
Потім ми визначаємо, які задачі виконуються в системі, використовуючи команду squeue. Поля показують ID задачі, розділ, назву, користувача, стан, час роботи, кількість та список вузлів. Подивіться сторінку man для більш конкретної інформації.
$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
65646 batch chem mike R 24:19 2 adev[7-8]
65647 batch bio joan R 0:09 1 adev14
65648 batch math phil PD 0:00 6 (Resources)
Команда scontrol дає більш детальну інформацію про вузли, розділи, задачі.
$ scontrol show partition
PartitionName=scit1 TotalNodes=24 TotalCPUs=48 RootOnly=NO
Default=NO Shared=NO Priority=1 State=UP MaxTime=44-10:40:00 Hidden=NO
MinNodes=1 MaxNodes=24 DisableRootJobs=NO AllowGroups=ALL
Nodes=n1[001-024] NodeIndices=0-23
PartitionName=scit2 TotalNodes=32 TotalCPUs=64 RootOnly=NO
Default=NO Shared=NO Priority=1 State=UP MaxTime=2-02:00:00 Hidden=NO
MinNodes=1 MaxNodes=UNLIMITED DisableRootJobs=NO AllowGroups=ALL
Nodes=n2[001-032] NodeIndices=24-55
PartitionName=scit3 TotalNodes=98 TotalCPUs=560 RootOnly=NO
Default=YES Shared=NO Priority=1 State=UP MaxTime=20-20:00:00 Hidden=NO
MinNodes=1 MaxNodes=UNLIMITED DisableRootJobs=NO AllowGroups=ALL
Nodes=n[3106-3125,3127-3143,3146-3150,3006-3010,3012-3017,3019-3025,3030-3038,3043-3069,3073-3074] NodeIndices=61-65,67-72,74-80,85-93,98-124,128-129,141-160,162-178,181-185
PartitionName=scit3gpu TotalNodes=4 TotalCPUs=8 RootOnly=NO
Default=NO Shared=NO Priority=1 State=UP MaxTime=44-10:40:00 Hidden=NO
MinNodes=1 MaxNodes=UNLIMITED DisableRootJobs=NO AllowGroups=ALL
Nodes=gpu[1-4] NodeIndices=188-191
PartitionName=lite_task TotalNodes=5 TotalCPUs=24 RootOnly=NO
Default=NO Shared=NO Priority=1 State=UP MaxTime=03:00:00 Hidden=NO
MinNodes=1 MaxNodes=UNLIMITED DisableRootJobs=NO AllowGroups=ALL
Nodes=n[3026-3029,3152] NodeIndices=81-84,187-187
Отримуємо детальну інформацію про вузол:
$ scontrol show node n3025
NodeName=n3025 State=ALLOCATED CPUs=4 AllocCPUs=4 RealMemory=7887 TmpDisk=0
Sockets=4 Cores=1 Threads=1 Weight=1 Features=(null) Reason=(null)
Arch=x86_64 OS=Linux
Інформація про задачу:
$ scontrol show job 36622
JobId=36622 UserId=xxxx(yyyy) GroupId=zzzz(zzzz)
Name=d-n35
Priority=4294878198 Partition=scit3 BatchFlag=1
AllocNode:Sid=access:23692 TimeLimit=20-20:00:00 ExitCode=0:0
JobState=RUNNING StartTime=06/01-19:09:01 EndTime=06/22-15:09:01
NodeList=n3025 NodeListIndices=80-80
AllocCPUs=4
ReqProcs=4 ReqNodes=1 ReqS:C:T=1-64.00K:1-64.00K:1-64.00K
Shared=0 Contiguous=0 CPUs/task=0 Licenses=(null)
MinProcs=1 MinSockets=1 MinCores=1 MinThreads=1
MinMemoryNode=0 MinTmpDisk=0 Features=(null)
Dependency=(null) Account=(null) Requeue=1
Reason=None Network=(null)
ReqNodeList=(null) ReqNodeListIndices=
ExcNodeList=(null) ExcNodeListIndices=
SubmitTime=06/01-19:09:01 SuspendTime=None PreSusTime=0
Command=/home/users/xxxxx/test/binary1 d-n35
WorkDir=/home/users/xxxxx/test
Отримати ресурси та запустити задачу можна командою srun. У цьому прикладі виконується задача /bin/hostname на трьох вузлах, використовується розділ за замовчуванням, один процес на вузол. У прикладі опція -l задає включення зазначення номера процесу на початку кожного рядка.
access$ srun -N3 -l /bin/hostname
0: node03
1: node04
2: node05
Це варіація попереднього прикладу, в якій виконуються 4 процеси /bin/hostname, всі на одному вузлі.
access$ srun -n4 -l /bin/hostname
0: node03
1: node03
2: node03
3: node03
Найбільш часто використовуваний спосіб роботи з кластером - постановка задач в чергу для виконання. Для цього замість srun слід використовувати команду sbatch, яка ставить задачу в чергу. Стандартний вивід задачі буде направлений в файл slurm-$jobid.out, а потік помилок у файл slurm-$jobid.err.
Розглянемо ще один варіант роботи - роздільне отримання ресурсів та запуск задач в межах виділених ресурсів. Команда salloc використовується, щоб створити виділений ресурс та отримати оболонку в межах цього виділеного ресурсу.
Після цього запускати кроки задачі можна командою srun. Після застосування останньої команди - exit, оболонка, створена salloc, нарешті буде завершена.
SLURM автоматично не переміщує виконувані файли програм або файли даних на виділені для задачі вузли. Файли повинні існувати або на локальному диску, або в якійсь глобальній файловій системі (наприклад NFS або Lustre).
SLURM надає інструмент sbcast для переміщення файлів в місцеве сховище на виділених вузлах. У цьому прикладі використовується sbcast, щоб перемістити програму a.out в /tmp/joe.a.out на виділені вузли. Після виконання програми ми видаляємо її з місцевого сховища.
access$ salloc -N10 bash
$ sbcast a.out /tmp/joe.a.out
Granted job allocation 471
$ srun /tmp/joe.a.out
Result is 3.14159
$ srun rm /tmp/joe.a.out
$ exit
salloc: Relinquishing job allocation 471
У цьому прикладі, ми подаємо пакетну задачу, отримуємо її статус та скасовуємо її.
access$ sbatch test
srun: jobid 473 submitted
access$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
473 batch test jill R 00:00 1 node09
access$ scancel 473
access$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
MPI
Характер використання MPI залежить від того, який вид MPI використовується. Є три відмінні одна від одної послідовності дій, що використовуються цими різними типами MPI.
- SLURM безпосередньо запускає задачу та виконує ініціалізацію комунікацій (MPICH2, MPICH-GM, MPICH-MX, MVAPICH, MVAPICH2 та деякі методи MPICH1).
- SLURM виділяє ресурси для задачі, а потім mpirun запускає задачу, використовуючи інфраструктуру SLURM (OPENMPI, LAM / MPI і HP-MPI).
- SLURM виділяє ресурси для задачі, а потім mpirun запускає задачу, використовуючи при цьому будь-який механізм, крім SLURM, як, наприклад, SSH або RSH (BlueGene MPI та деякі методи MPICH1). Ці задачі ініціюються за межами області, яку контролює або бачить SLURM. Тому в скрипті епілогу (epilog) SLURM необхідно передбачити засоби примусового зупину процесів, щоб можна було позбутися цієї задачі, коли у неї заберуть виділені для неї ресурси.
Підтримка Мульти-ядерних/Багатопотокових Архітектур
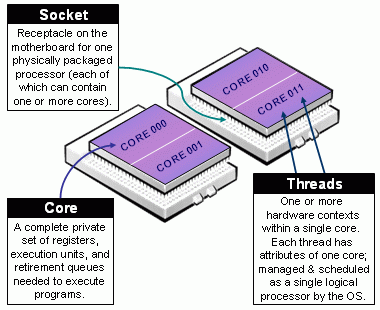
Socket/Core/Thread - ілюструє поняття Гнізда, Ядра та Нитки так, як це визначається в документації SLURM.